
Welcome back! Last time we saw eachother, I didn’t have much to showcase. But I’ve been hard at work since then. A little thing about me is, I love taking on ambitious projects that push my boundaries. Today, I’m thrilled to pull back the curtain on my latest endeavor: Storks Ride Share. It’s not a personal project per-se, but let’s just say, It is kind of my brain child.
As a university student, we have usually two projects per semester. But usually they tend to be what you would expect. A CRUD application, or something focused. Fortunately, this semester, I got the chance to work on a project that is completely meant to imitate a industry standard project. I’d be a fool if I didn’t take the chance to actually mimic an industry like workflows.
When I, and my team members (yes, it was a group project. I’ll write seperately on the experience of it later on) were first introduced to the project brief, we were instructed to specifically to either find an actual client, or try to find a real-life problem, that we can find a solution to. We decided to go with the latter.
There were multiple ideas, that was thrown around. I didn’t have much expectations going into the project (as I have had some bad runs with prior group projects), but after the initial conversations with my fellow team members, I was pretty optimistic. The idea didn’t take much time to come, but it took a while to be refined. As such, We decided to go with an idea that was a bit ambitious. A ride-sharing application, similar to Uber or PickMe but specifically tailored toward school children in Sri Lanka. Our inside joke was that the elevator pitch for this was “Uber for schoolvans”.

Storks: Secure Ride for your precious~
Storks wasn’t meant to be just a simple CRUD application. It was built to be a fully-fledged, real-time ride-sharing ecosystem. From managing concurrent driver locations to orchestrating complex booking workflows, I wanted to build a system that mirrored industry standards. And we did. So, let’s dive into how I approached this challenge, guided my teammates, the technical hurdles we faced, and the architecture behind the system.
The Core: What should we build?
Our initial idea was simple: Uber for schoolvans. A platform to connect parents with reliable van drivers for their children’s daily commutes.
But as we brainstormed, the idea evolved. We realized the core pain points for parents in Sri Lanka:
- Safety concerns: Traditional van services often lack transparency and security measures.
- Reliability: Drivers can be unreliable, leading to disruptions in children’s routines.
- Convenience: Parents struggle to find and coordinate with reliable van drivers.
We decided to build a platform that addresses these pain points by providing a secure, reliable, and convenient solution for parents and drivers.
The Challenge: Why Microservices?
In the initial conversations we had about the system. We went back and forth a couple of times on how we should design the system. The core problems we had to asnwer was security, connectivity, and concurrency. How do we ensure that the system is secure? How do we ensure that the system is connected? How do we ensure that the system is concurrent? Can we actually build a system that is scalable, reliable, and maintainable?
Taking our system requirements into account; We identified that we would need 6 core components in our system:
- User Management
- Safety and Verification
- Ride Management
- Location Management
- Payment Management
- Matching and Navigation Intelligence
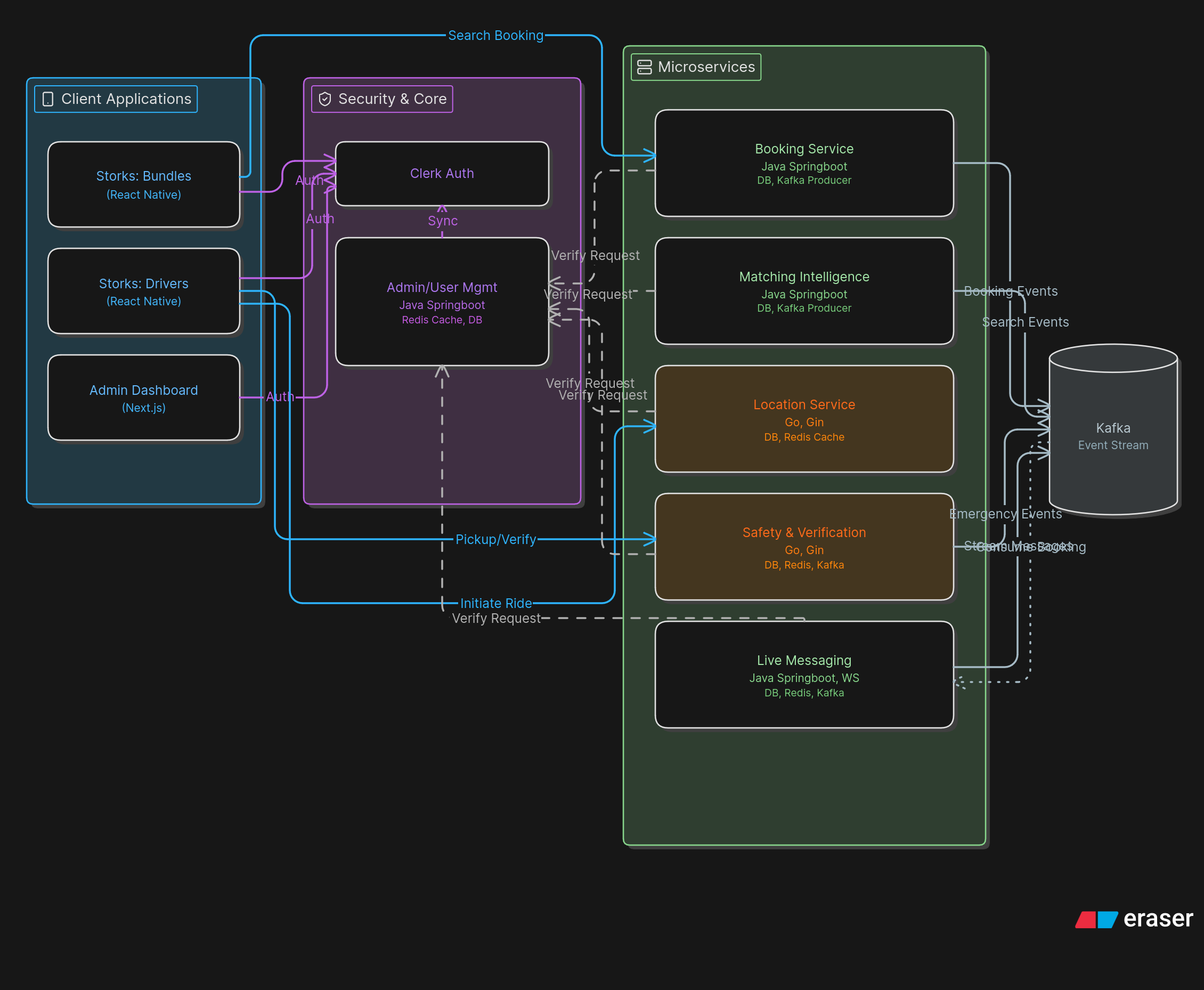
They have their own characteristics. If I bundled the heavy I/O of real-time location updates with the transactional nature of user bookings, the entire system’s performance would suffer under load.
The first thought was going for a simple monolithic architecture. A single repository, a single database, a single entry point for the entire system. And that…didn’t quite feel right. As such, I recommended going for a polyrepository architecture, dividing each core component of the system into its own service, with its own database. This would be the best way to scale the project if needed.
From the beginning, we didn’t approach this project as a academic project. Trying our best to view it from a deployable, scalable, real life service. But upon considerations we realized, for a project that is constrained into a six month timeline, going for a polyrepo architecture was just using a shovel to eat soup. So as usual, we improvised. A single repo, divided into microservices.
The Process: Choosing the Right Tool for the Job
Then came another question, this, to be truthfully a happy accident that happened to work out in favour for us. Going into the project, I personally wanted to try out GO, just trying to spread my wings out from the usual languages. But not all my teammembers were on board with that, so as usual, we compromised. After realizing the Pros of using Go language on real time services, we decided to utilise both Java and Go rather than over-engineering a custom solution from scratch or sticking strictly to one language. This was how we decided to jump in and build a polyglot microservices architecture.
We needed a robust, battle-tested framework for complex business logic, and something incredibly fast and lightweight for the high-frequency services. The decision? A combination of Java (Spring Boot) and Go, tied together by Apache Kafka.
Bridging Java and Go with Kafka
Project Structure
To keep the ecosystem manageable, I organized the codebase as a monorepo, maintaining shared libraries and consistent configurations across services. Here’s a glimpse of what that looks like:
Technical Deep Dive
Let’s look at how the core pieces fit together to create a seamless experience.
1. High-Performance Services with Go
The Location Service and Safety Service are written in Go. Why Go? Because handling a massive influx of real-time telemetry data requires minimal overhead. Go’s concurrency model—specifically Goroutines—makes it trivial to spin up lightweight threads to handle incoming location payloads simultaneously without choking the CPU.
This allowed the Location Service to ingest GPS coordinates, update redis caches for real-time driver visibility, and publish events for other services, all with sub-millisecond latency.
2. Core Business Logic with Java & Spring Boot
For services like Booking, User Management, and Matching Intelligence, I relied on Java 21 and Spring Boot. These domains are heavily relational and require complex transactional boundaries (e.g., verifying a user’s identity, locking a booking, and executing the matching algorithm). Spring Boot’s mature ecosystem and robust data-handling capabilities made it the perfect fit here.
3. Event-Driven Communication via Apache Kafka
This is where the magic happens. To avoid tight coupling and synchronous API bottlenecks, I implemented an event-driven architecture using Apache Kafka.
When a parent requests a ride via the Booking Service, we don’t directly call the Matching Intelligence service. Instead:
- The Booking Service publishes a
RideRequestedEventto a Kafka topic. - The Matching Intelligence service consumes this event, runs its algorithm against available drivers (fetched via Redis from the Location Service), and proposes a match.
This creates a highly resilient system. If the Matching service goes down, the Booking service can still accept requests, and the Kafka queue will process once the service recovers.
4. Shared Infrastructure
Everything is underpinned by a robust shared infrastructure:
- PostgreSQL as the primary relational database, cleanly segmented per service.
- Redis for distributed caching and rapid session lookups.
- Docker & Docker Compose for seamless local development and containerization, allowing the entire stack to boot up via a single
docker-compose upcommand.
Looking Forward
Building Storks Ride Share has been an incredible journey. It pushed me to think deeply about system design, data boundaries, and distributed communication. While I’m proud of the current architecture, software is never truly “finished.”
My backlog is already filled with ideas: migrating the deployment to Kubernetes, expanding the basic monitoring features to a more finer-grained observability with Prometheus and Grafana, and refining the algorithms inside the Matching Intelligence service.
Thank you for taking the time to read through my process! If you are a fellow engineer or a recruiter looking for someone who loves diving deep into distributed systems, I’d love to connect. Feel free to check out my GitHub GitHub or reach out via email at hello@kavindunirmal.com.
Until next time, happy coding!